Les méthodes de normalisation des données sont utilisées pour que les variables, mesurées à différentes échelles, aient des valeurs comparables. Cette étape de prétraitement est importante pour le regroupement et la visualisation des heatmap, l’analyse en composantes principales et d’autres algorithmes d’apprentissage machine basés sur des mesures de distance.
Cet article décrit les approches suivantes en matière de normalisation et de standardisation des données:
- Normalisation standard ou standardisation
- Normalisation entre 0 et 1 ou normalisation Min-Max
- Transformation en percentile
Des codes seront fournis pour démontrer comment standardiser, normaliser et percentiliser les données dans R. Le package R heatmaply contient des fonctions d’aide pour normaliser et visualiser les données sous forme de heatmap interactive.
Sommaire:
Prérequis
Le package R heatmaply sera utilisé pour visualiser interactivement les données avant et après la transformation.
Installez les packages en utilisant install.packages("heatmaply"), puis chargez-le comme suit:
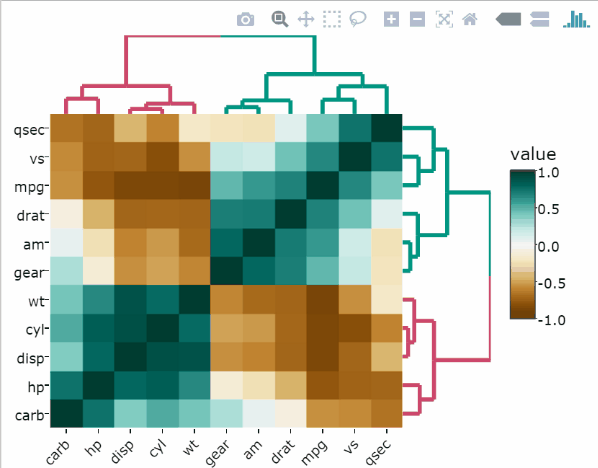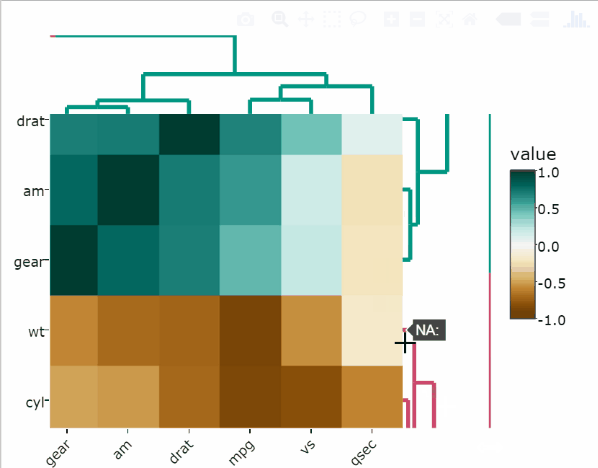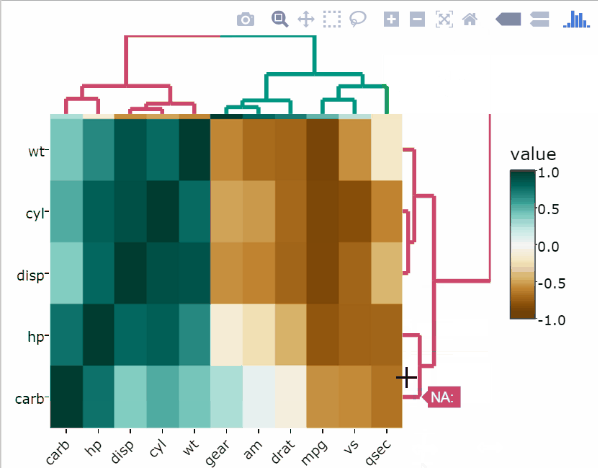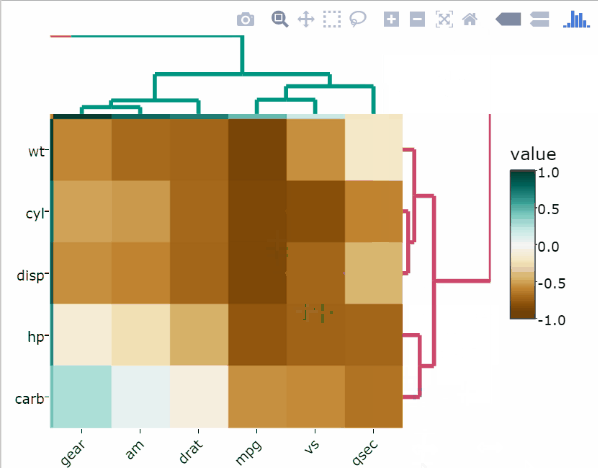
library(heatmaply)Heatmap des données brutes
heatmaply(
mtcars,
xlab = "Features",
ylab = "Cars",
main = "Raw data"
)Normalisation standard
La normalisation standard, également appelée standardisation ou normalisation z-score, consiste à soustraire la moyenne et à la diviser par l’écart type. Dans ce cas, chaque valeur refléterait la distance par rapport à la moyenne en unités d’écart-type.
Si nous supposons que toutes les variables proviennent d’une distribution normale, la normalisation z-score les rapprocherait toutes de la distribution normale standard. La distribution résultante a une moyenne de 0 et un écart-type de 1.
Formule de la normalisation standard:
\[Transformed.Values = \frac{Values - Mean}{Standard.Deviation}\]
Une alternative à la standardisation z-score est la normalisation de moyenne, dont la distribution résultante sera entre -1 et 1 avec une moyenne = 0.
Formule de la normalisation de moyenne:
\[Transformed.Values = \frac{Values - Mean}{Maximum - Minimum}\]
La normalisation z-core et la normalisation de moyenne peuvent être utilisées pour les algorithmes qui supposent des données centrées sur le zéro, comme l’analyse en composantes principales (ACP).
Le code R suivant normalise le jeu de données mtcars et crée une heatmap:
heatmaply(
scale(mtcars),
xlab = "Features",
ylab = "Cars",
main = "Data Scaling"
)Normalisation
Lorsque les variables des données proviennent de distributions éventuellement différentes (et non normales), d’autres transformations peuvent être nécessaires. Une autre possibilité consiste à normaliser les variables pour amener les données sur l’échelle de 0 à 1 en soustrayant le minimum et en divisant par le maximum de toutes les observations.
Cela préserve la forme de la distribution de chaque variable tout en les rendant facilement comparables sur la même “échelle”.
Formulation pour normaliser les données entre 0 et 1 :
\[Transformed.Values = \frac{Values - Minimum}{Maximum - Minimum}\]
Formule permettant de redimensionner les données entre un ensemble de valeurs arbitraires [a, b]:
\[
Transformed.Values = a + \frac{(Values - Minimum)(b-a)}{Maximum - Minimum}
\]
où “a,b” sont les valeurs min-max.
Normaliser les données dans R. L’utilisation de la fonction de normalisation Min-Max sur les données de mtcars révèle facilement des colonnes avec seulement deux (am, vs) ou trois (gear, cyl) variables par rapport aux variables qui ont une plus grande résolution des valeurs possibles:
heatmaply(
normalize(mtcars),
xlab = "Features",
ylab = "Cars",
main = "Data Normalisation"
)Transformation en percentile
Une alternative à la fonction normaliser est la fonction percentile. Cette méthode est similaire au classement des variables, mais au lieu de conserver les valeurs de classement, il faut les diviser par le rang maximal. Pour ce faire, on utilise l'ecdf des variables sur leurs propres valeurs, en amenant chaque valeur à son percentile empirique. L’avantage de la fonction de percentile est que chaque valeur a une interprétation relativement claire, c’est le pourcentage d’observations avec cette valeur ou en dessous de celle-ci.
heatmaply(
percentize(mtcars),
xlab = "Features",
ylab = "Cars",
main = "Percentile Transformation"
)Notez que pour les variables binaires (0 et 1), la transformation du percentile transformera toutes les valeurs 0 en leur proportion et toutes les valeurs 1 resteront 1. Cela signifie que la transformation n’est pas symétrique pour 0 et 1. Par conséquent, en cas de normalisation pour le regroupement, il peut être préférable d’utiliser le rang pour traiter les doublons (si aucun doublon n’est présent, le percentile aura une performance similaire au rang).
Références
Version:
 English
English




No Comments