Cet article décrit les hypothèses du test t indépendant et fournit des exemples de code R pour vérifier si les hypothèses sont respectées avant de calculer le test t. C’est ce qu’on appelle également les hypothèses du test t à deux échantillons.
Le t-test pour échantillons indépendants se présente sous deux formes différentes:
- le test t standard de Student, qui suppose que la variance des deux groupes est égale.
- le test t de Welch, qui est moins restrictif que le test original de Student. Il s’agit du test où vous ne présumez pas que la variance est la même dans les deux groupes, ce qui donne les degrés de liberté fractionnaires suivants.
Les deux méthodes donnent des résultats très semblables, à moins que la taille des groupes et les écarts-types ne soient très différents.
Sommaire:
Livre Apparenté
Pratique des Statistiques dans R II - Comparaison de Groupes: Variables NumériquesHypothèses
Le test t pour échantillons indépendant assume les caractéristiques suivantes au sujet des données:
- Indépendance des observations. Chaque sujet ne doit appartenir qu’à un seul groupe. Il n’y a aucun lien entre les observations de chaque groupe.
- Aucune valeur aberrante significative dans les deux groupes
- Normalité. les données pour chaque groupe devraient être distribuées approximativement normalement.
- Homogénéité des variances. la variance de la variable-réponse devrait être égale dans chaque groupe. Rappelons que le test t de Welch ne fait pas ces hypothèses.
Dans cette section, nous effectuerons quelques tests préliminaires pour vérifier si ces hypothèses sont respectées.
Vérifier les hypothèses du test t indépendant dans R
Prérequis
Assurez-vous d’avoir installé les paquets R suivants:
tidyversepour la manipulation et la visualisation des donnéesggpubrpour créer facilement des graphiques prêts à la publicationrstatixcontient des fonctions R facilitant les analyses statistiques.datarium: contient les jeux de données requis pour ce chapitre.
Commencez par charger les packages requis suivants:
library(tidyverse)
library(ggpubr)
library(rstatix)Données de démonstration
Jeu de données de démonstration : genderweight [package datarium] contenant le poids de 40 individus (20 femmes et 20 hommes).
Charger les données et afficher quelques lignes aléatoires par groupes:
# Charger les données
data("genderweight", package = "datarium")
# Afficher un échantillon des données par groupe
set.seed(123)
genderweight %>% sample_n_by(group, size = 2)## # A tibble: 4 x 3
## id group weight
## <fct> <fct> <dbl>
## 1 6 F 65.0
## 2 15 F 65.9
## 3 29 M 88.9
## 4 37 M 77.0Identifier les valeurs aberrantes
Les valeurs aberrantes peuvent être facilement identifiées à l’aide des méthodes boxplot, implémentées dans la fonction R identify_outliers() [paquet rstatix].
genderweight %>%
group_by(group) %>%
identify_outliers(weight)## # A tibble: 2 x 5
## group id weight is.outlier is.extreme
## <fct> <fct> <dbl> <lgl> <lgl>
## 1 F 20 68.8 TRUE FALSE
## 2 M 31 95.1 TRUE FALSEIl n’y avait pas de valeurs extrêmes aberrantes.
Notez que, dans le cas où vous avez des valeurs extrêmes aberrantes, cela peut être dû à : 1) erreurs de saisie de données, erreurs de mesure ou valeurs inhabituelles.
Vous pouvez de toute façon inclure la valeur aberrante dans l’analyse si vous ne croyez pas que le résultat sera affecté de façon substantielle. Cela peut être évalué en comparant le résultat du test t avec et sans la valeur aberrante.
Il est également possible de conserver les valeurs aberrantes dans les données et d’effectuer un test Wilcoxon ou un test t robuste en utilisant le progiciel WRS2.
Vérifier la normalité par groupes
L’hypothèse de normalité peut être vérifiée en calculant le test de Shapiro-Wilk pour chaque groupe. Si les données sont normalement distribuées, la p-value doit être supérieure à 0,05.
genderweight %>%
group_by(group) %>%
shapiro_test(weight)## # A tibble: 2 x 4
## group variable statistic p
## <fct> <chr> <dbl> <dbl>
## 1 F weight 0.938 0.224
## 2 M weight 0.986 0.989D’après le résultat, les deux p-values sont supérieures au seuil de significativité 0,05, ce qui indique que la distribution des données n’est pas significativement différente de la distribution normale. En d’autres termes, nous pouvons supposer que la normalité.
Vous pouvez également créer des QQ plots pour chaque groupe. Le graphique QQ plot dessine la corrélation entre une donnée définie et la distribution normale.
ggqqplot(genderweight, x = "weight", facet.by = "group")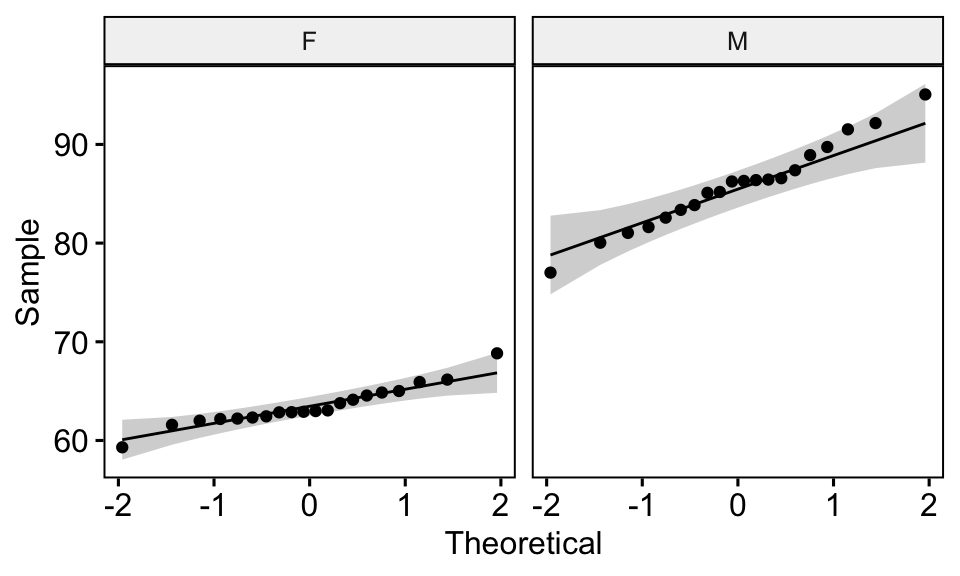
Tous les points se situent approximativement le long de la ligne de référence (45 degrés), pour chaque groupe. Nous pouvons donc supposer la normalité des données.
Notez que, si la taille de votre échantillon est supérieure à 50, le graphique de normalité QQ plot est préféré parce qu’avec des échantillons de plus grande taille, le test de Shapiro-Wilk devient très sensible même à un écart mineur par rapport à la distribution normale.
Il est à noter que, dans le cas où les données ne sont pas normalement distribuées, il est recommandé d’utiliser le test de Wilcoxon non paramétrique à deux échantillons.
Vérifier l’égalité des variances
Ceci peut être fait à l’aide du test de Levene. Si les variances des groupes sont égales, la p-value doit être supérieure à 0,05.
genderweight %>% levene_test(weight ~ group)## # A tibble: 1 x 4
## df1 df2 statistic p
## <int> <int> <dbl> <dbl>
## 1 1 38 6.12 0.0180La p-value du test de Levene est significative, ce qui suggère qu’il existe une différence significative entre les variances des deux groupes. Par conséquent, nous utiliserons le test t de Welch, qui ne suppose pas l’égalité des deux variances.
Article apparenté
Version:
 English
English

No Comments