Le test de Friedman est une alternative non paramétrique au test ANOVA, à un facteur, sur mesures répétées. Il étend le test du signe dans le cas où il y a plus de deux groupes à comparer.
Le test de Friedman est utilisé pour évaluer s’il existe des différences statistiquement significatives entre les distributions de trois groupes appariés ou plus. Il est recommandé lorsque les hypothèses de normalité du test ANOVA, à un facteur, sur mesures répétées ne sont pas respectées ou lorsque la variable dépendante est mesurée sur une échelle ordinale.
Dans ce chapitre, vous apprendrez à:
- Calculer le test de Friedman dans R
- Effectuer des comparaisons multiples par paire entre les groupes, afin d’identifier les paires de groupes qui sont significativement différentes.
- Déterminer la taille de l’effet du test de Friedman à l’aide du W de Kendall.
Sommaire:
Livre Apparenté
Pratique des Statistiques dans R II - Comparaison de Groupes: Variables NumériquesPrérequis
Assurez-vous d’avoir installé les paquets R suivants:
tidyversepour la manipulation et la visualisation des donnéesggpubrpour créer facilement des graphiques prêts à la publicationrstatixoffre des fonctions R conviviales pour des analyses statistiques faciles à réaliser.
Charger les packages:
library(tidyverse)
library(ggpubr)
library(rstatix)Préparation des données
Nous utiliserons le jeu de données sur l’estime de soi mesuré sur trois points temporels. Les données sont disponibles dans le package datarium.
data("selfesteem", package = "datarium")
head(selfesteem, 3)## # A tibble: 3 x 4
## id t1 t2 t3
## <int> <dbl> <dbl> <dbl>
## 1 1 4.01 5.18 7.11
## 2 2 2.56 6.91 6.31
## 3 3 3.24 4.44 9.78Rassemblez les colonnes t1, t2 et t3 en format long. Convertir les variables id et time en factor (ou variables de regroupement):
selfesteem <- selfesteem %>%
gather(key = "time", value = "score", t1, t2, t3) %>%
convert_as_factor(id, time)
head(selfesteem, 3)## # A tibble: 3 x 3
## id time score
## <fct> <fct> <dbl>
## 1 1 t1 4.01
## 2 2 t1 2.56
## 3 3 t1 3.24Statistiques descriptives
Calculer quelques statistiques sommaires du score de l’estime de soi par groupe (time):
selfesteem %>%
group_by(time) %>%
get_summary_stats(score, type = "common")## # A tibble: 3 x 11
## time variable n min max median iqr mean sd se ci
## <fct> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 t1 score 10 2.05 4.00 3.21 0.571 3.14 0.552 0.174 0.395
## 2 t2 score 10 3.91 6.91 4.60 0.89 4.93 0.863 0.273 0.617
## 3 t3 score 10 6.31 9.78 7.46 1.74 7.64 1.14 0.361 0.817Visualisation
Créer un box plot et ajouter des points correspondant à des valeurs individuelles
ggboxplot(selfesteem, x = "time", y = "score", add = "jitter")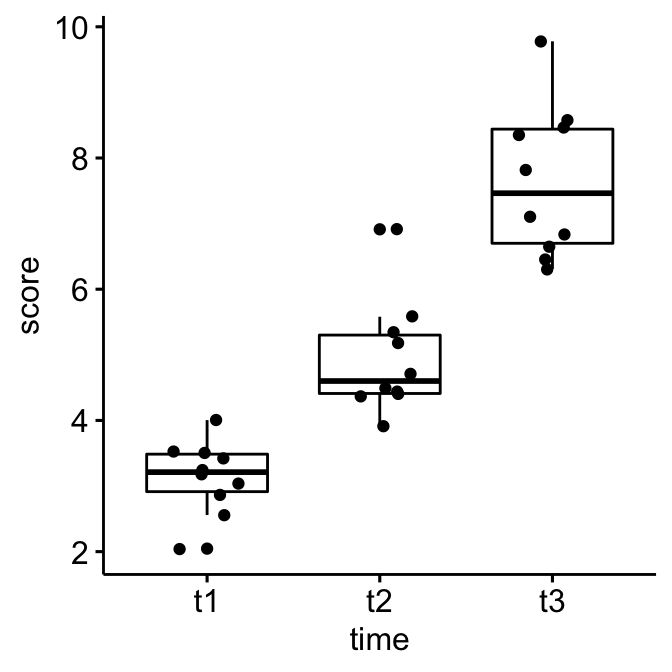
Calculs
Nous utiliserons la fonction friedman_test() [paquet rstatix], un wrapper autour de la fonction de base R friedman.test().
res.fried <- selfesteem %>% friedman_test(score ~ time |id)
res.fried## # A tibble: 1 x 6
## .y. n statistic df p method
## * <chr> <int> <dbl> <dbl> <dbl> <chr>
## 1 score 10 18.2 2 0.000112 Friedman testLe score de l’estime de soi était statistiquement significativement différent aux différents temps durant le régime, X2(2) = 18,2, p = 0,0001.
Taille de l’effet
Le W de Kendall peut être utilisé comme mesure de la taille de l’effet du test de Friedman. Il se calcule comme suit : W = X2/N(K-1) ; où W est la valeur W de Kendall ; X2 est la valeur statistique du test de Friedman ; N est la taille de l’échantillon. k est le nombre de mesures par sujet (M. T. Tomczak and Tomczak 2014).
Le coefficient W de Kendall prend la valeur de 0 (indiquant l’absence de relation) à 1 (indiquant une relation parfaite).
Le W de Kendall utilise les recommandations d’interprétation de Cohen: 0,1 - < 0,3 (petit effet), 0,3 - < 0,5 (effet modéré) et >= 0,5 (effet important). Les intervalles de confiance sont calculés par bootstap.
selfesteem %>% friedman_effsize(score ~ time |id)## # A tibble: 1 x 5
## .y. n effsize method magnitude
## * <chr> <int> <dbl> <chr> <ord>
## 1 score 10 0.910 Kendall W largeUne grande taille d’effet est détectée, W = 0,91.
Comparaisons multiples par paires
D’après les résultats du test de Friedman, nous savons qu’il y a une différence significative entre les groupes, mais nous ne savons pas quelles paires de groupes sont différentes.
Un test de Friedman significatif peut être suivi de tests des rangs de Wilcoxon pour identifier quels groupes sont différents.
Notez que les données doivent être correctement ordonnées par la variable de bloc (id) pour que la première observation du temps t1 soit appariée avec la première observation du temps t2, et ainsi de suite.
Comparaisons par paires à l’aide du test apparié des rangs signés de Wilcoxon. Les p-values sont ajustées à l’aide de la méthode de correction des tests multiples de Bonferroni.
# comparaisons par paires
pwc <- selfesteem %>%
wilcox_test(score ~ time, paired = TRUE, p.adjust.method = "bonferroni")
pwc## # A tibble: 3 x 9
## .y. group1 group2 n1 n2 statistic p p.adj p.adj.signif
## * <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <chr>
## 1 score t1 t2 10 10 0 0.002 0.006 **
## 2 score t1 t3 10 10 0 0.002 0.006 **
## 3 score t2 t3 10 10 1 0.004 0.012 *Toutes les différences par paires sont statistiquement significatives.
Notez qu’il est également possible d’effectuer des comparaisons par paires à l’aide du test de signe, qui peut manquer de puissance pour détecter les différences dans les jeux de données appariés. Cependant, il est utile parce qu’il ne comporte que peu d’hypothèses sur les distributions des données à comparer.
Comparaisons par paires à l’aide du test des signes:
pwc2 <- selfesteem %>%
sign_test(score ~ time, p.adjust.method = "bonferroni")
pwc2Rapporter
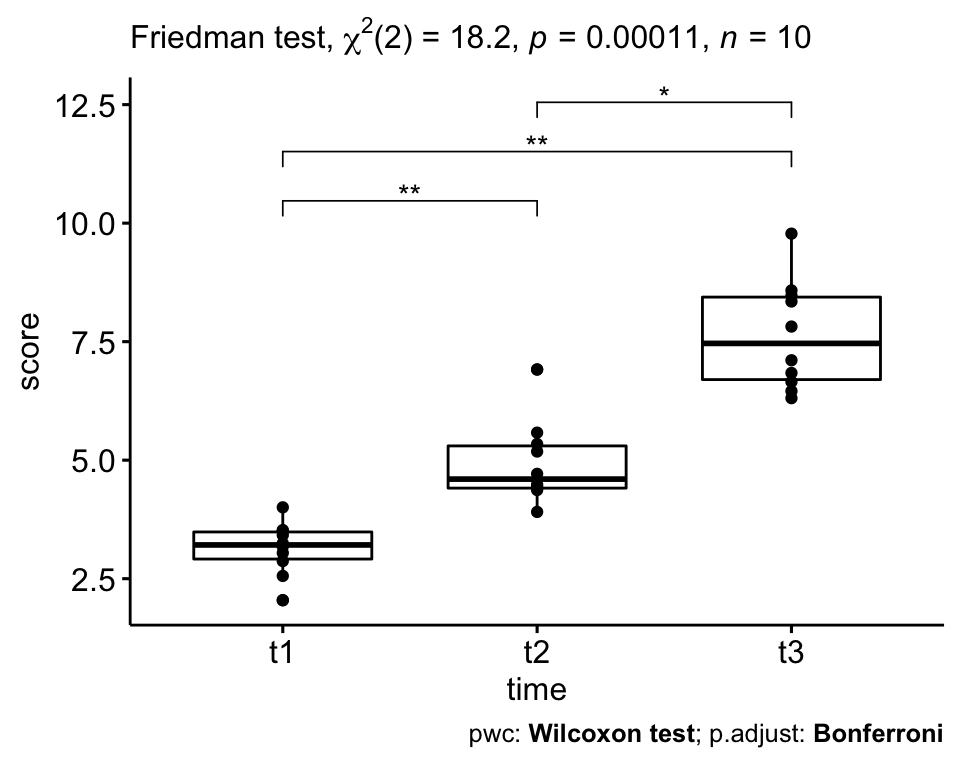
Le score de l’estime de soi était statistiquement significativement différent aux différents points de temps en utilisant le test de Friedman, X2(2) = 18,2, p = 0,00011.
Le test des rangs signés de Wilcoxon entre les groupes a révélé des différences statistiquement significatives dans le score d’estime de soi entre t1 et t2 (p = 0,006) ; t1 et t3 (0,006) ; t2 et t3 (0,012).
# Visualisation : Boxplots avec p-values
pwc <- pwc %>% add_xy_position(x = "time")
ggboxplot(selfesteem, x = "time", y = "score", add = "point") +
stat_pvalue_manual(pwc, hide.ns = TRUE) +
labs(
subtitle = get_test_label(res.fried, detailed = TRUE),
caption = get_pwc_label(pwc)
)
References
Tomczak, Maciej T., and Ewa Tomczak. 2014. “The Need to Report Effect Size Estimates Revisited. an Overview of Some Recommended Measures of Effect Size.” Trends in SportSciences.
Version:
 English
English

Bonjour Alboukadel,
merci pour ce tuto intéressant et bien expliqué.
Dans le cas ou les hypothèses de normalité du test ANOVA ne sont pas respectées et que variable dépendante n’est pas dans une échelle ordinale. Le test de Friedman peut être appliqué? En effet j’ai des paramètres qui ont été mesurés chez le même sujet dans 4 conditions. Je souhaite faire une ANOVA pour voir si les paramètres ne sont pas différents entre les conditions.
Bonjour Alboukadel,
tuto très intéressant et explicite comme d’habitude, encore merci. Le test de Friedman peut elle être appliqué dans le cas de données appariés ne satisfaisant pas les conditions de normalité et dont la variable étudiée n’est pas ordidane.
Un exemple de mes données
ID Tube Var
1 Tube 1 90450
2 Tube 1 90915
3 Tube 1 76666
4 Tube 1 70470
5 Tube 1 108416
6 Tube 1 89443
7 Tube 1 87740
8 Tube 1 84952
9 Tube 1 76743
10 Tube 1 81235
11 Tube 1 84177
12 Tube 1 102995
13 Tube 1 92463
14 Tube 1 105551
15 Tube 1 112830
1 Tube 2 81854
2 Tube 2 88359
3 Tube 2 75349
4 Tube 2 70006
5 Tube 2 105783
6 Tube 2 86965
7 Tube 2 85184
8 Tube 2 78137
9 Tube 2 96026
10 Tube 2 81699
11 Tube 2 83480
12 Tube 2 101059
13 Tube 2 92076
14 Tube 2 104002
15 Tube 2 110584
1 Tube 3 88824
2 Tube 3 89366
3 Tube 3 75659
4 Tube 3 71555
5 Tube 3 106635
6 Tube 3 88436
7 Tube 3 87043
8 Tube 3 77827
9 Tube 3 92463
10 Tube 3 80460
11 Tube 3 83093
12 Tube 3 101988
13 Tube 3 92231
14 Tube 3 102531
15 Tube 3 110120
1 Tube 4 88127
2 Tube 4 88746
3 Tube 4 75814
4 Tube 4 71012
5 Tube 4 106712
6 Tube 4 88669
7 Tube 4 86423
8 Tube 4 78911
9 Tube 4 97962
10 Tube 4 80228
11 Tube 4 85107
12 Tube 4 102376
13 Tube 4 91069
14 Tube 4 101446
15 Tube 4 108958
Merci d’avance
Bonjour Alboukadel,
tuto très intéressant et explicite comme d’habitude, encore merci. Le test de Friedman peut elle être appliqué dans le cas de données appariés ne satisfaisant pas les conditions de normalité et dont la variable étudiée n’est pas ordinale (erreur de ma part).
Un exemple de mes données
ID Tube Var
1 Tube 1 90450
2 Tube 1 90915
3 Tube 1 76666
4 Tube 1 70470
5 Tube 1 108416
6 Tube 1 89443
7 Tube 1 87740
8 Tube 1 84952
9 Tube 1 76743
10 Tube 1 81235
11 Tube 1 84177
12 Tube 1 102995
13 Tube 1 92463
14 Tube 1 105551
15 Tube 1 112830
1 Tube 2 81854
2 Tube 2 88359
3 Tube 2 75349
4 Tube 2 70006
5 Tube 2 105783
6 Tube 2 86965
7 Tube 2 85184
8 Tube 2 78137
9 Tube 2 96026
10 Tube 2 81699
11 Tube 2 83480
12 Tube 2 101059
13 Tube 2 92076
14 Tube 2 104002
15 Tube 2 110584
1 Tube 3 88824
2 Tube 3 89366
3 Tube 3 75659
4 Tube 3 71555
5 Tube 3 106635
6 Tube 3 88436
7 Tube 3 87043
8 Tube 3 77827
9 Tube 3 92463
10 Tube 3 80460
11 Tube 3 83093
12 Tube 3 101988
13 Tube 3 92231
14 Tube 3 102531
15 Tube 3 110120
1 Tube 4 88127
2 Tube 4 88746
3 Tube 4 75814
4 Tube 4 71012
5 Tube 4 106712
6 Tube 4 88669
7 Tube 4 86423
8 Tube 4 78911
9 Tube 4 97962
10 Tube 4 80228
11 Tube 4 85107
12 Tube 4 102376
13 Tube 4 91069
14 Tube 4 101446
15 Tube 4 108958
Merci d’avance