Ce chapitre décrit comment transformer des données en distribution normale dans R. Les méthodes paramétriques, comme le test t et les tests ANOVA, supposent que la variable dépendante (réponse) est approximativement distribuée normalement pour chaque groupe à comparer.
Dans le cas où l’hypothèse de normalité n’est pas respectée, vous pourriez envisager de transformer les données pour corriger les distributions non normales.
Lorsqu’il s’agit d’hypothèses de test t et d’ANOVA, il suffit de transformer la variable dépendante. Cependant, lorsqu’il s’agit d’hypothèses de régression linéaire, vous pouvez considérer les transformations de la variable indépendante ou dépendante ou des deux pour obtenir une relation linéaire entre les variables ou pour vous assurer qu’il y a homoscédasticité.
Notez que la transformation ne sera pas toujours réussie.
Dans cet article, vous apprendrez:
- Les types courants de distributions non normales
- Les méthodes de transformation des données pour corriger les distributions non normales
Sommaire:
Livre Apparenté
Pratique des Statistiques dans R II - Comparaison de Groupes: Variables NumériquesDistributions non normales
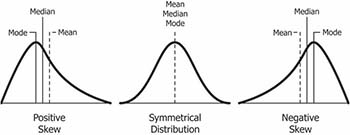
L’asymétrie est une mesure de la symétrie d’une distribution. La valeur peut être positive, négative ou indéfinie. Dans une distribution asymétrique, les mesures de tendance centrale (moyenne, médiane, mode) ne seront pas égales.
(source : https://www.safaribooksonline.com/library/view/clojure-for-data/9781784397180/ch01s13.html)
- Distribution positivement asymétrique (ou asymétrique à droite) : Les valeurs les plus fréquentes sont basses ; la queue est vers les valeurs élevées (sur le côté droit). En général,
Mode < Median < Mean. - Distribution négativement asymétrique (ou asymétrique à gauche), les valeurs les plus fréquentes sont élevées ; la queue est vers les valeurs faibles (sur le côté gauche). En général,
Mode > Median > Mean.
La direction de l’asymétrie est donnée par le signe du coefficient d’asymétrie:
- Un zéro signifie aucune asymétrie du tout (distribution normale).
- Une valeur négative signifie que la distribution est négativement asymétrique.
- Une valeur positive signifie que la distribution est positivement asymétrique.
Plus la valeur de l’asymétrie est élevée, plus la distribution diffère d’une distribution normale.
Le coefficient d’asymétrie peut être calculé à l’aide du paquet R moments:
library(moments)
skewness(iris$Sepal.Length, na.rm = TRUE)## [1] 0.312Méthodes de transformation
Cette section décrit différentes méthodes de transformation, en fonction du type de violation de la normalité.
Voici quelques transformations heuristiques courantes pour les données non normales:
- racine carrée pour biais modéré:
sqrt(x)pour les données asymétriques positives,sqrt(max(x+1) - x)pour les données asymétriques négatives
- log pour une plus grande asymétrie:
log10(x)pour les données asymétriques positives,log10(max(x+1) - x)pour les données asymétriques négatives
- inverse pour une asymétrie sévère:
1/xpour les données asymétriques positives1/(max(x+1) - x)pour les données asymétriques négatives
- Linéarité et hétéroscédasticité:
- essayez d’abord la transformation
logdans une situation où la variable dépendante commence à augmenter plus rapidement avec l’augmentation des valeurs des variables indépendantes - Si vos données font le contraire - les valeurs des variables dépendantes diminuent plus rapidement avec l’augmentation des valeurs des variables indépendantes - vous pouvez d’abord envisager une transformation
carrée.
- essayez d’abord la transformation
Notez que, lors de l’utilisation d’une transformation logarithmique, une constante doit être ajoutée à toutes les valeurs pour les rendre toutes positives avant transformation.
Exemples de transformation de données asymétriques
Prérequis
Assurez-vous d’avoir installé les paquets R suivants:
ggpubrpour créer facilement des graphiques prêts à la publicationmomentspour le calcul de l’asymétrie
Commencez par charger les paquets:
library(ggpubr)
library(moments)Jeu de données de démonstration : Jeu de données intégré dans R USJudgeRatings.
data("USJudgeRatings")
df <- USJudgeRatings
head(df)## CONT INTG DMNR DILG CFMG DECI PREP FAMI ORAL WRIT PHYS RTEN
## AARONSON,L.H. 5.7 7.9 7.7 7.3 7.1 7.4 7.1 7.1 7.1 7.0 8.3 7.8
## ALEXANDER,J.M. 6.8 8.9 8.8 8.5 7.8 8.1 8.0 8.0 7.8 7.9 8.5 8.7
## ARMENTANO,A.J. 7.2 8.1 7.8 7.8 7.5 7.6 7.5 7.5 7.3 7.4 7.9 7.8
## BERDON,R.I. 6.8 8.8 8.5 8.8 8.3 8.5 8.7 8.7 8.4 8.5 8.8 8.7
## BRACKEN,J.J. 7.3 6.4 4.3 6.5 6.0 6.2 5.7 5.7 5.1 5.3 5.5 4.8
## BURNS,E.B. 6.2 8.8 8.7 8.5 7.9 8.0 8.1 8.0 8.0 8.0 8.6 8.6Dans les exemples suivants, nous allons considérer deux variables:
CONT: Nombre de contacts de l’avocat avec le juge. Positivement asymétrique.PHYS: Aptitude physique. Négativement asymétrique
Visualisation
Tracez la distribution de densité de chaque variable et comparez la distribution observée à ce à quoi nous pourrions nous attendre si elle était parfaitement normale (ligne rouge en pointillés).
# Distribution de la variable CONT
ggdensity(df, x = "CONT", fill = "lightgray", title = "CONT") +
scale_x_continuous(limits = c(3, 12)) +
stat_overlay_normal_density(color = "red", linetype = "dashed")
# Distribution de la variable PHYS
ggdensity(df, x = "PHYS", fill = "lightgray", title = "PHYS") +
scale_x_continuous(limits = c(3, 12)) +
stat_overlay_normal_density(color = "red", linetype = "dashed")![]()
![]()
La variable “CONT” montre une asymétrie positive. La variable “PHYS” est négativement asymétrique
Calculer l’asymétrie:
skewness(df$CONT, na.rm = TRUE)## [1] 1.09skewness(df$PHYS, na.rm = TRUE)## [1] -1.56Transformation logarithmique des données asymétriques:
df$CONT <- log10(df$CONT)
df$PHYS <- log10(max(df$CONT+1) - df$CONT)# Distribution de la variable CONT
ggdensity(df, x = "CONT", fill = "lightgray", title = "CONT") +
stat_overlay_normal_density(color = "red", linetype = "dashed")
# Distribution de la variable PHYS
ggdensity(df, x = "PHYS", fill = "lightgray", title = "PHYS") +
stat_overlay_normal_density(color = "red", linetype = "dashed")![]()
![]()
Calculer l’asymétrie sur les données transformées:
skewness(df$CONT, na.rm = TRUE)## [1] 0.656skewness(df$PHYS, na.rm = TRUE)## [1] -0.818La transformation log10 améliore la distribution des données vers la normalité.
Résumé et discussion
Cet article décrit comment transformer les données pour la normalité, une hypothèse requise pour les tests paramétriques tels que les tests t et les tests ANOVA.
Dans le cas où l’hypothèse de normalité n’est pas respectée, vous pourriez envisager d’exécuter les tests statistiques (test t ou ANOVA) sur les données transformées et non transformées pour voir s’il y a des différences significatives.
Si les deux tests vous amènent aux mêmes conclusions, vous pourriez choisir de ne pas transformer la variable-réponse et de continuer avec les résultats des tests sur les données originales.
Notez que la transformation rend l’interprétation de l’analyse beaucoup plus difficile. Par exemple, si vous exécutez un test t pour comparer la moyenne de deux groupes après avoir transformé les données, vous ne pouvez pas simplement dire qu’il y a une différence dans les moyennes des deux groupes. Maintenant, vous avez l’étape supplémentaire d’interpréter le fait que la différence est basée sur la transformation logarithmique. Pour cette raison, les transformations sont généralement évitées à moins que cela ne soit nécessaire pour que l’analyse soit valide.
Dans le cas d’analyses comme la famille de tests F ou t (c.-à-d. les tests t d’échantillons indépendants et dépendants, ANOVA, MANOVA et les régressions), les violations de la normalité ne constituent habituellement pas une peine de mort pour la validité. Avec des échantillons suffisamment grands (> 30 ou 40), il y a de bonnes chances que les données soient distribuées normalement ; ou au moins assez près de la distribution normale pour que vous puissiez vous en tirer avec des tests paramétriques (théorème central limite).
Version:
 English
English

Bonjour,
Très bel article. Néanmoins, pour la transformée en Log, il faudrait avoir des données qui soient positives. Dans mon étude économétrique, j’ai une variable synthétique qui prend des valeurs négatives. Y a-t-il un moyen de les normaliser? Vu que j’ai besoin d’executer l’étude en utilisant des transformées Log.
En effet, comme vous l’avez souligné, la transformation log ne peut s’appliquer que sur des valeurs positives.
Une technique courante pour traiter les valeurs négatives consiste à ajouter une valeur constante aux données avant d’appliquer la transformation logarithmique. La transformation est donc
log(x + constante).Certaines personnes aiment choisir la constante de sorte que
min(x + constante)soit un très petit nombre positif (comme 0,001).D’autres choisissent la constante de sorte que
min(x + constante) = 1. Dans ce cas, la constante à prendre peut être definie commeconstante = b - min(x), où b est soit un petit nombre, soit 1. C’est à vous de choisir. Dans l’exemple, ci-dessous j’ai choisib = 1:Il faudrait voir si de telle approache est applicable dans votre étude économétrique.
J’ai du mal a comprendre pourquoi la transformation en log de la variable « phys » depend de la variable « cont ».
pourquoi ne pas faire df$phys<- log10(df$phys)?
Comment interpréter le CV pour les données de comptage(souvent très variées) de 0 on peut aller 10 15 voire même 20 et souvent avec beaucoup de zéro. Le CV peut -il être choisi pour apprécier de telle variable
J’adore vos post toujours tres clair! pourriez vous expliquer si il est permis de faire une nromalisation par log pour petits echantillons et ensuite faire un rescaling si nous avons des variables (biologique) numeriques qui sont a des echelles differentes? Doit on traiter les outliers prealablement a toute transformation?
Bonjour, Merci pour votre post très complet. Néanmoins, dans le cas d’une assymétrie négative, le changement sqrt(max(x+1) – x) ou log10(max(x+1) – x) va changer l’ordre des variables (i.e. le territoire le plus chaud en température va devenir le plus froid par exemple). Ne faut-il rajouter un signe moins devant ? (dans le cas où on fait des changements différents sur nos variables et qu’on les utilise après pour faire des modèles).