This article describes the one sample t-test assumptions and provides examples of R code to check whether the assumptions are met before calculating the t-test.
Contents:
Related Book
Practical Statistics in R II - Comparing Groups: Numerical VariablesAssumptions
The one-sample t-test assumes the following characteristics about the data:
- No significant outliers in the data
- Normality. the data should be approximately normally distributed
In this section, we’ll perform some preliminary tests to check whether these assumptions are met.
Check one-sample t-test assumptions in R
Prerequisites
Make sure you have installed the following R packages:
ggpubrfor creating easily publication ready plotsrstatixprovides pipe-friendly R functions for easy statistical analyses.datarium: contains required data sets for this chapter.
Start by loading the following required packages:
library(ggpubr)
library(rstatix)Demo data
Demo dataset: mice [in datarium package]. Contains the weight of 10 mice:
# Load and inspect the data
data(mice, package = "datarium")
head(mice, 3)## # A tibble: 3 x 2
## name weight
## <chr> <dbl>
## 1 M_1 18.9
## 2 M_2 19.5
## 3 M_3 23.1Identify outliers
Outliers can be easily identified using boxplot methods, implemented in the R function identify_outliers() [rstatix package].
mice %>% identify_outliers(weight)## [1] name weight is.outlier is.extreme
## <0 rows> (or 0-length row.names)There were no extreme outliers.
Note that, in the situation where you have extreme outliers, this can be due to: 1) data entry errors, measurement errors or unusual values.
In this case, you could consider running the non parametric Wilcoxon test.
Check normality assumption
The normality assumption can be checked by computing the Shapiro-Wilk test. If the data is normally distributed, the p-value should be greater than 0.05.
mice %>% shapiro_test(weight)## # A tibble: 1 x 3
## variable statistic p
## <chr> <dbl> <dbl>
## 1 weight 0.923 0.382From the output, the p-value is greater than the significance level 0.05 indicating that the distribution of the data are not significantly different from the normal distribution. In other words, we can assume the normality.
You can also create a QQ plot of the weight data. QQ plot draws the correlation between a given data and the normal distribution.
ggqqplot(mice, x = "weight")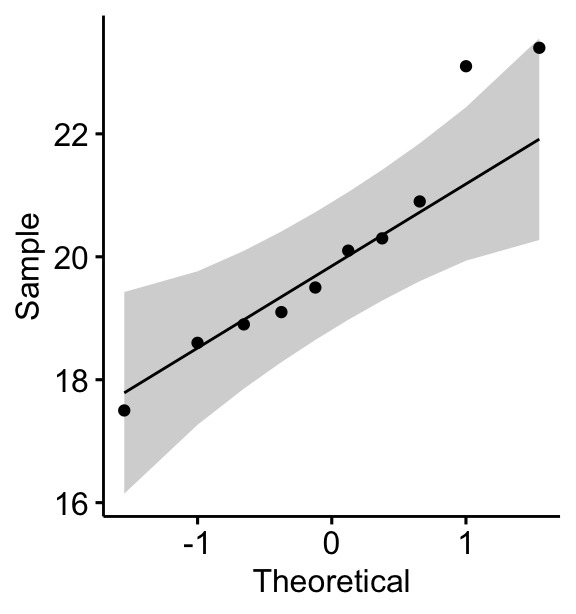
All the points fall approximately along the (45-degree) reference line, for each group. So we can assume normality of the data.
Note that, if your sample size is greater than 50, the normal QQ plot is preferred because at larger sample sizes the Shapiro-Wilk test becomes very sensitive even to a minor deviation from normality.
If the data are not normally distributed, it’s recommended to use a non-parametric test such as the one-sample Wilcoxon signed-rank test. This test is similar to the one-sample t-test, but focuses on the median rather than the mean.
Recommended for you
This section contains best data science and self-development resources to help you on your path.
Books - Data Science
Our Books
- Practical Guide to Cluster Analysis in R by A. Kassambara (Datanovia)
- Practical Guide To Principal Component Methods in R by A. Kassambara (Datanovia)
- Machine Learning Essentials: Practical Guide in R by A. Kassambara (Datanovia)
- R Graphics Essentials for Great Data Visualization by A. Kassambara (Datanovia)
- GGPlot2 Essentials for Great Data Visualization in R by A. Kassambara (Datanovia)
- Network Analysis and Visualization in R by A. Kassambara (Datanovia)
- Practical Statistics in R for Comparing Groups: Numerical Variables by A. Kassambara (Datanovia)
- Inter-Rater Reliability Essentials: Practical Guide in R by A. Kassambara (Datanovia)
Others
- R for Data Science: Import, Tidy, Transform, Visualize, and Model Data by Hadley Wickham & Garrett Grolemund
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems by Aurelien Géron
- Practical Statistics for Data Scientists: 50 Essential Concepts by Peter Bruce & Andrew Bruce
- Hands-On Programming with R: Write Your Own Functions And Simulations by Garrett Grolemund & Hadley Wickham
- An Introduction to Statistical Learning: with Applications in R by Gareth James et al.
- Deep Learning with R by François Chollet & J.J. Allaire
- Deep Learning with Python by François Chollet
Version:
 Français
Français

No Comments