Introduction
Web scraping is a powerful technique to extract data from websites for analysis, research, or other data-driven projects. In this tutorial, you’ll learn how to use BeautifulSoup—a popular Python library—to parse HTML and extract meaningful information from web pages. We’ll cover not only basic examples like extracting page titles and links, but also advanced techniques such as extracting tables, handling pagination, and using sessions to maintain state across multiple requests.
Importing Required Packages
To keep our code organized and avoid repetition, we start by importing the necessary packages. This ensures that all subsequent code chunks have access to the required libraries.
# | label: import-packages
# This code imports the essential packages for web scraping.
import requests
from bs4 import BeautifulSoupBasic Web Scraping Example
First, let’s demonstrate how to fetch a webpage, parse its HTML, and extract the page title.
# | label: basic-scraping
# Define the URL to scrape
url = "https://www.worldometers.info/world-population/population-by-country/"
# Fetch the webpage
response = requests.get(url)
# Parse the HTML content
soup = BeautifulSoup(response.text, "html.parser")
# Extract and print the page title
page_title = soup.title.string
print("Page Title:", page_title)Output:
Page Title: Population by Country (2025) - WorldometerExtracting Tables
Many websites present data in tables. You can use BeautifulSoup to extract table data and convert it into a structured format.
# | label: extract-tables
# Find a table by its tag (or with additional attributes, e.g., class or id)
table = soup.find("table")
# Extract table headers
headers = [header.text.strip() for header in table.find_all("th")]
# Extract table rows
rows = []
for row in table.find_all("tr")[1:]:
cells = [cell.text.strip() for cell in row.find_all("td")]
if cells:
rows.append(cells)
# Create a `DataFrame` using the extracted headers and rows
df = pd.DataFrame(rows, columns=headers)
df.head()
Handling Pagination
For websites that display data over multiple pages, you can automate the process of iterating through pages.
The following script scrapes the blog posts by extracting each post’s title (from the anchor text) and URL (from the anchor’s href attribute):
# | label: pagination-example
import time
def scrape_page(url):
response = requests.get(url)
return BeautifulSoup(response.text, "html.parser")
# The website uses a query parameter "#listing-listing-page=" for pagination
base_url = "https://quarto.org/docs/blog/#listing-listing-page="
page_number = 1
all_data = []
# Example: scrape first 2 pages
while page_number <= 2:
url = base_url + str(page_number)
soup = scrape_page(url)
# Extract blog posts:
# Each title and URL is within an `<h3 class="no-anchor listing-title">`
posts = []
for h3 in soup.find_all("h3", class_="no-anchor listing-title"):
a_tag = h3.find("a")
if a_tag:
title = a_tag.text.strip()
link = a_tag.get("href")
posts.append({"title": title, "url": link})
all_data.extend(posts)
page_number += 1
# Respectful delay between requests
time.sleep(1)
# Convert the output to a DataFrame and print the data
df = pd.DataFrame(all_data)
df.head()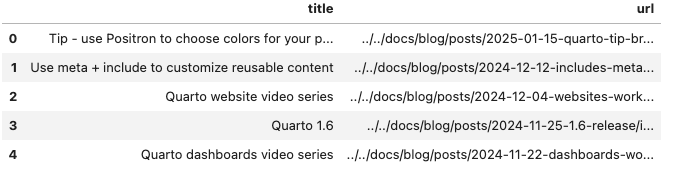
How It Works
- Pagination: The script builds the URL for each page using a query parameter (e.g.,
#listing-listing-page=1,#listing-listing-page=2). - Scraping the Page: For each page, the
scrape_pagefunction downloads and parses the HTML. - Extracting Posts: It looks for
<h3>tags with the class"no-anchor listing-title", finds the child<a>tag, and extracts the title (using.text) and the URL (using.get("href")). - Collecting Data: Each post’s data is stored as a dictionary in the
all_datalist.
Using Sessions
When scraping multiple pages from the same website, using a session can improve performance by reusing settings (like headers and cookies) and maintaining state.
# | label: using-sessions
# Create a session object
session = requests.Session()
session.headers.update({"User-Agent": "Mozilla/5.0"})
# Use the session to make requests
url = "https://www.worldometers.info/world-population/population-by-country/"
response = session.get(url)
soup = BeautifulSoup(response.text, "html.parser")
print("Session-based Page Title:", soup.title.string)Best Practices for Web Scraping
Respect Website Policies:
Always check a site’srobots.txtand terms of service before scraping.Rate Limiting:
Use delays (e.g.,time.sleep()) between requests to avoid overwhelming the website.Error Handling:
Incorporate robust error handling to manage connection issues and unexpected HTML structures.
Ensure that your web scraping activities comply with legal and ethical guidelines.
Conclusion
Web scraping with BeautifulSoup is an effective way to extract and process data from websites. By combining basic techniques with advanced strategies like table extraction, pagination handling, and session management, you can build robust data collection pipelines for your data science projects. Experiment with these examples, adjust them to fit your specific needs, and always practice ethical scraping.
Further Reading
- Python Automation: Scheduling and Task Automation
- Building REST APIs with FastAPI: A Modern Python Framework
- Unit Testing in Python with pytest: A Comprehensive Guide
Happy coding, and enjoy exploring the power of web scraping with BeautifulSoup!
Explore More Articles
Here are more articles from the same category to help you dive deeper into the topic.
Reuse
Citation
@online{kassambara2024,
author = {Kassambara, Alboukadel},
title = {Web {Scraping} with {BeautifulSoup}},
date = {2024-02-08},
url = {https://www.datanovia.com/learn/programming/python/tools/web-scraping-with-beautifulsoup.html},
langid = {en}
}